Hi guys, back with another #CloudGuruChallenge.
This time, it is all about a multi-cloud madness inspired by @ScottPletcher from ACG. The goal of this challenge is to architect and build an image upload and recognition process using no less than three different cloud providers.
Feel free to read about the challenge instructions here.
Whilst it seems to be simple, there is still a big uncertainty because the architecture is spanning across three different cloud providers.
Here is my approach to this challenge.
Overview
I will go through the overall choice of architecture and services for the app and how I deployed it. All pertaining code can be find here.
Application web UI
About the App
The app functionality is simple on its own. It just provides analysis data from an uploaded image. The data is then stored into a NoSQL database along with the path to the image. The uploaded image + data are also displayed back to the user.
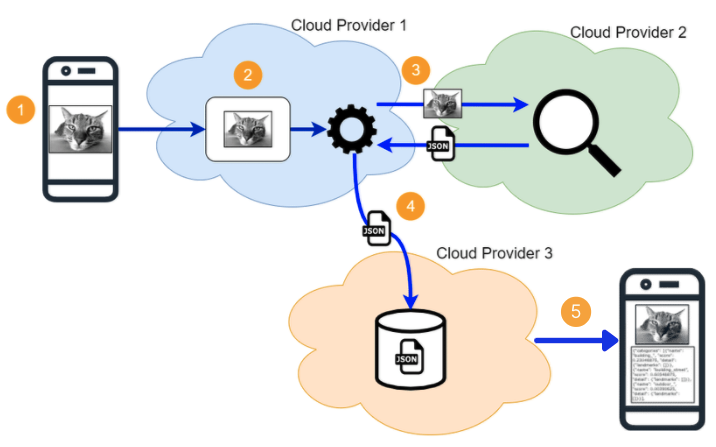
Application Components
Now that we have a basic understanding of the app, let's see how all of these functionalities translate to different technical components. Below image should provide a good overview of each layer of the app and the technical components involved.
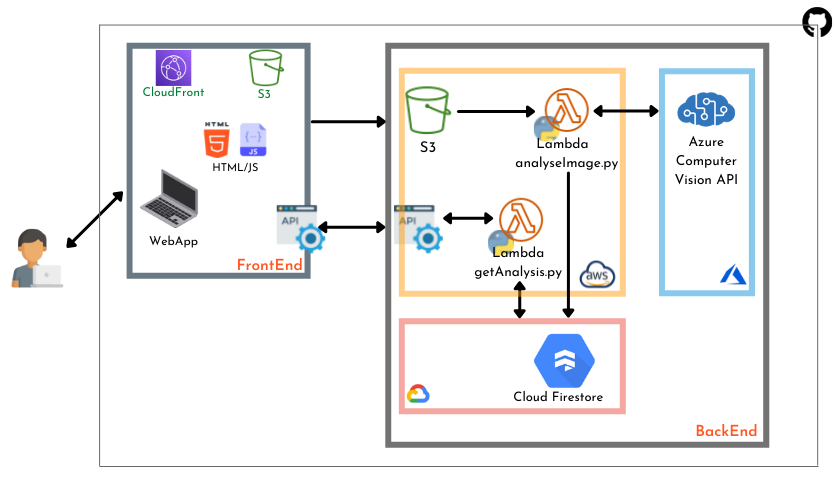
Let's go through each component.
Frontend
The Frontend for the app is built of simple HTML and Javascript. There are two points of communication with the backend:
Upload an Image: I have used Javascript SDK to store the uploaded image on S3. Before being uploaded, the name of the file is made unique using UUID. This name is saved and later used to retrieve the image's data.
Get analysis data of the uploaded image: the frontend calls an API which triggers a Lambda function. The above saved file name is sent as path parameter.
Backend
I decided to host the brain of the app on AWS. This part of the infrastructure is basically made of Lambda functions and API Gateway.
For image recognition, I've used Azure Computer Vision API, and to save the results, I've opted for Google Cloud Firestore.
This setup is really efficient as it mostly uses managed services from the different cloud providers.
We will not have to manage servers or extra configuration - other than those required to make the services work together.
Now that we have information about the various components and services involved in the app, let's focus on how to integrate them in other to obtain a technical architecture.
Architecture
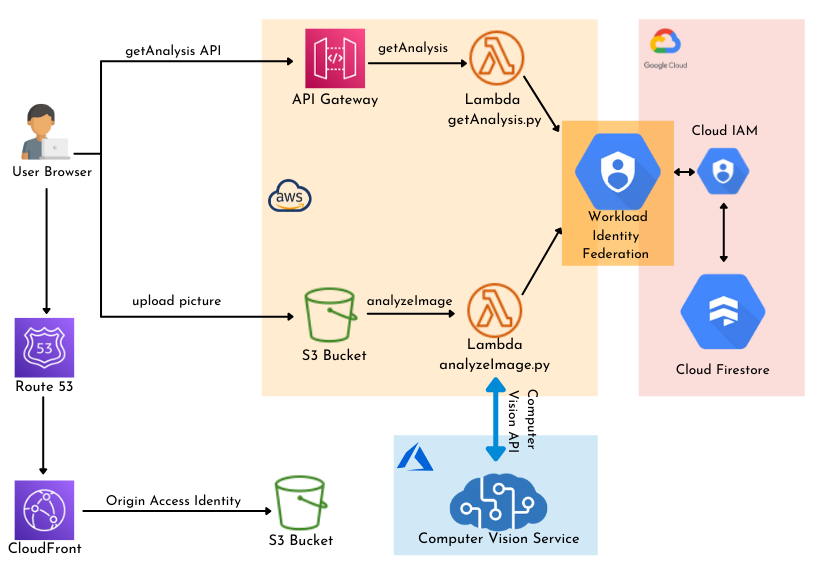
Frontend
Website: The static html, javascript and css files generated for the website will be stored in an S3 bucket. The S3 bucket is configured to host a website and will provide an endpoint through which the app can be accessed. To have a better performance on the frontend, the S3 bucket is selected as an Origin to a CloudFront distribution. The CloudFront will act as a CDN for the app frontend and provide faster access through the app pages.
Upload picture: A Javascript function handles the file upload to a separate S3 bucket (files bucket). Before being uploaded, the name of the file is made unique using UUID. The function saves the file name in a local storage variable. This name is later used as the path parameter of the request sent to the API to retrieve image's data.
Backend
Our application's backend relies on services from all 3 providers. Let's break it down.
Azure
The purpose of our app being to extract rich information from images, I have decided to give Azure Cognitive services a try and deployed a Computer Vision API to serve this purpose.
The service is fairly easy to deploy and offers a publicly accessible API which can be integrated with the other parts of the app.
Since the API is accessible through the internet, we don't have to worry much about extra config to allow the communication. An access key is provided to add to your request when calling the API (although not the most secure option).
AWS
On the AWS side we have deployed two Lambda functions to handle the application logic.
analyzeImage: triggered when an image is added to the files bucket. Retrieves the file url from the events and send a request to the publicly accessible Azure Computer Vision API.
The response of this request contains the analysis data and is store in a dictionary.
The function now stores the data into a Cloud Firestore database collection. A new document is created in the collection for each analysis.
getAnalysis: retrieves the data store in the Cloud Firestore based on the file name. This function is backing a REST API to communicate with the frontend.
We can see that both lambda functions interact with the Cloud Firestore database hosted in GCP. Additional configuration is required for communication between AWS and GCP resources. More on that later.
GCP
Here we will deploy the NoSQL database to store the analysis data. We will create a Cloud Firestore collection and use the SDK for python to perform read and write operations.
Access GCP resources from AWS
GCP Workload Identity federation will allow us to access GCP resources from AWS without the need for service account keys.
How it works
Workload identity federation contains two components: workload identity pools and workload identity providers.
Workload identity pools is a logical container of external identities (in our case AWS roles), whereas Workload identity providers are the entities that contain the relative metadata about the relationship between the external identity provider (AWS, Azure. etc.) and GCP. For example, providers can contain information like AWS account IDs, IAM role ARNs, etc.
In addition to these components, we need to configure attribute mappings. Attributes are metadata attached to the external identity token that supply information to GCP via attribute mappings. Attributes can be combined with conditions to secure your tokens so that they can only be used by approved external identities during the workload identity federation process. Examples of attributes include name, email, or user ID.
Accessing GCP from AWS
gcloud iam workload-identity-pools create REPLACE_ME_POOL_ID \
- GCP: Create an Identity pool provider
gcloud iam workload-identity-pools providers create-aws REPLACE_ME_PROVIDER_NAME \
GCP: Create a Service Account - needed to give access to the GCP services that our lambda access, in our case Cloud Firestore:
roles/iam.workloadidentityuser (to impersonate the SA)
roles/datastore.user (read and write on firestore database)
GCP: Allow External Identities to impersonate a service account - required to allow AWS services (our lambda functions) access the GCP resources with the same roles and permissions as the service account created above
gcloud iam service-accounts add-iam-policy-binding awsrole@datapath.iam.gserviceaccount.com \
- GCP: Generate Google credentials - will be used in the lambda functions by exposing the GOOGLE_APPLICATION_CREDENTIALS environment variable.
gcloud iam workload-identity-pools create-cred-config \
projects/REPLACE_ME_GCP_PROJECT_ID/locations/global/workloadIdentityPools/REPLACE_ME_POOL_ID/providers/REPLACE_ME_PROVIDER_NAME \
Note: All CLI commands are done in the GCP console.
The diagram bellow describes the exchange process before our resources in AWS can access the Firestore database in GCP.
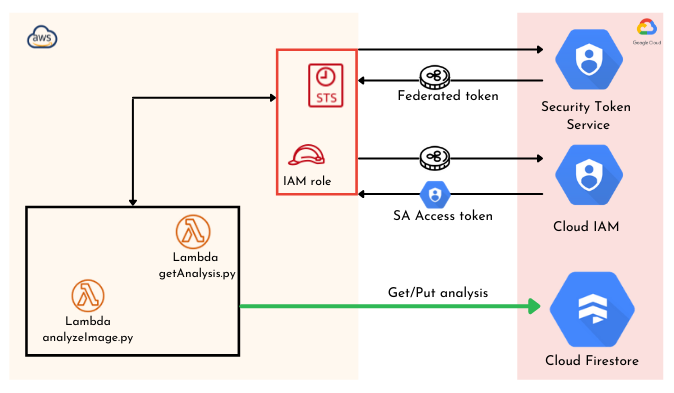
To better understand it, please refer to this blog which outlines the different steps involved.
IaC and Deployment Method
The application frontend and backend services hosted on AWS are defined as SAM templates. I have created two different stacks which contain resources from each side.
Although I could have used a solution like Terraform (which I am yet to learn and master) to codify the entire infrastructure, I decided to deploy the Azure Computer Vision API and the GCP Firestore database directly from the console and CLI.
As for automated deployments, I am comfortable using GitHub Actions as I find it easy to understand.
Each service - frontend and backend - is deployed using a separate deployment pipeline as follow:
Frontend
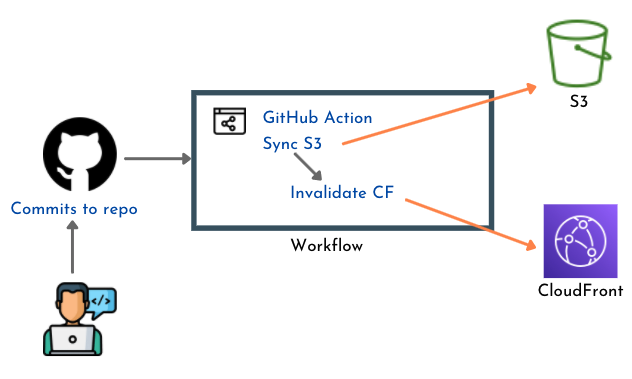
AWS Backend
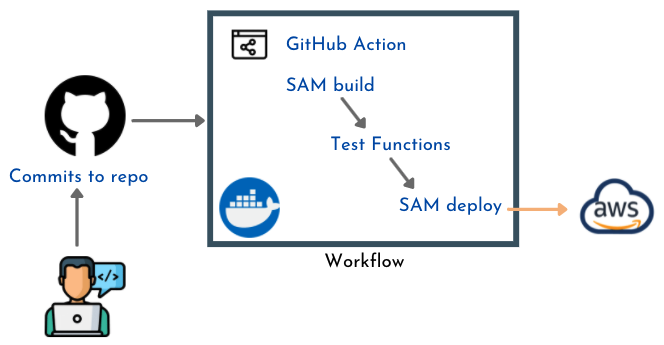
Takeaways
Although presenting some benefits for reliability, a multi-cloud architecture presents a lot of concerns when it comes to security, and it think this is what this cloud guru challenge is all about.
Communication from AWS resources to GCP services used to be implemented by creating a Service Account - a special type of Google account intended to represent a non-human user that needs to authenticate and be authorized to access data in GCP. This approach represent a big security risk because it relies on service account keys (file containing authentication info) to access GCP APIs.
By using workload identity federation, we adopt a more secure method (keyless application authentication mechanism) which allows applications running in AWS (or Azure or on-premises) to federate with an external Identity Provider and call Google Cloud resources without using a service account key. Hopefully I was able to show you how this works in a real environment.
As a next step, I am planning to make access between cloud providers totally private (abstracted from the internet). Don't know how to do it yet, but we'll figure it out!
As always feel free to let me know in the comments section, how you'd have complete this challenge.
