Deploying a sample to-do app on AWS - Container Version
👋 Hi, I’m @hpfpv ☁️ I’m a Cloud Infrastructure Architect | 8x AWS Certified 🚀 I build secure, scalable, and automated solutions on AWS using Terraform, CloudFormation, and CI/CD 📚 Always exploring hybrid cloud, serverless, and AI-driven architectures
Hi guys!
Recently I have been studying for the new AWS SysOps certification (which I passed already) and as you may already know, this exam is more on the practical side of things. Since I am not currently employed as a Cloud Engineer/Cloud Administrator, I decided to build and deploy a container version of my sample serverless to-do app in other to prepare for the most technical aspects of the exam.
The application's goal remains the same - allow logged-in users to manage their to-do list. The underlining architecture however will change a lot, especially the backend.
Services like ECS and ECR, Elastic Load Balancers and Autoscaling Group, API Gateway, and Cognito will be leveraged. We will make sure that our resources are securely deployed behind a VPC with the proper subnet configuration (NACLs, Route Tables, and Security groups), and will deploy a highly available application across availability zones. We also want to build a resilient application, properly monitored and maintained with appropriate CloudWatch alarms and actions (auto repairs, scaling policies...).
Overview & Basic Functionality
Refer to my previous blog post to get an overview of the application and learn more about its functionalities. All the code can be found here. There is no running demo for this app but you can still check out the serverless version's UI here.
Application Components
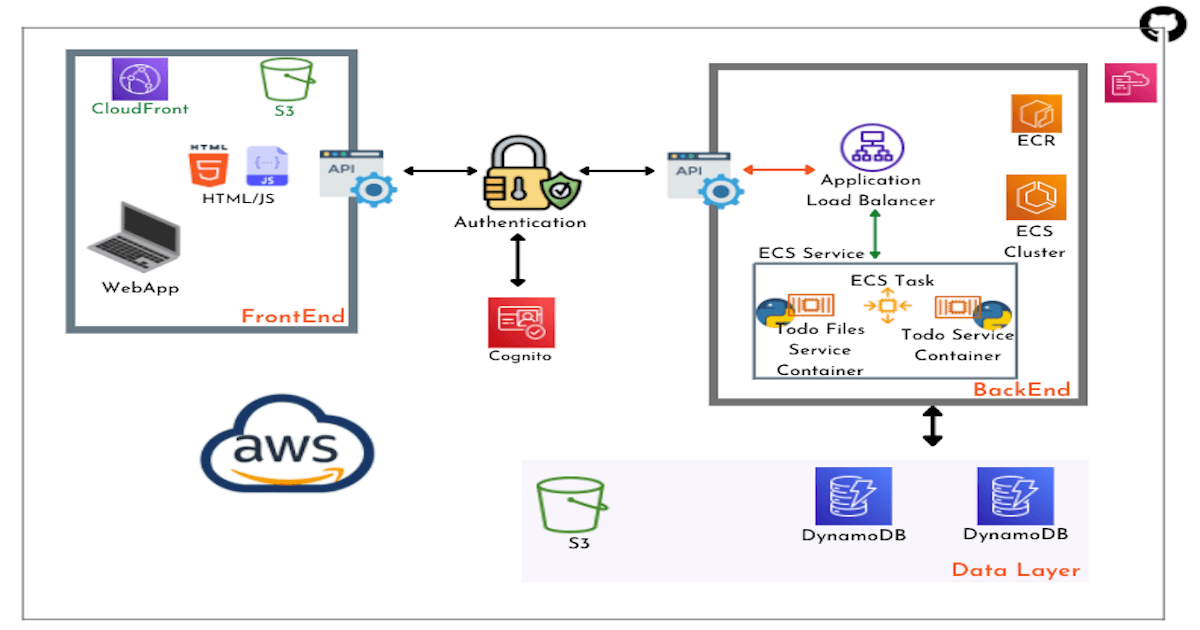
The biggest change with this version of the application is that we decided to deploy services backed by docker containers. And since we are deploying on AWS, Elastic Container Service is our choice to host our backend containers. Along with ECS, we need to have a well-defined VPC with networks spanning multiple availability zones for HA. The below image should provide a good overview of each layer of the app and especially the technical components involved in the backend.
Let's go through our backend layer components:
Services container
The application services (Main and File services) are coded as Python functions served via a Flask App. The Flask server is responsible for routing the requests to the corresponding functions i.e.
# get todos for the provided path parameter userID
@app.route('/<userID>/todos', methods=['GET'])
def getTodos(userID):
foo bar...
...
return todolist # as JSON
Even though both services use the same design, they are built-in 2 separate container images stored in the AWS Elastic Container Registry. The reason for that choice is for the purpose of decoupling - to isolate the services so that an issue with one container does not affect the whole application.
When building the container image, make sure to provide a specific tag and version as it is going to be used and eventually modified (version) during deployments. You should also avoid using latest for your production images; it refers to the latest image built without a version specified. Your deployment/update pipeline should add a version to modified images.
ECS Service and Cluster
ECS allows you to run and maintain a specified number of instances of a task definition simultaneously in an Amazon ECS cluster (logical group of services). This is called a service. It defines the deployment configuration for your tasks. I like to compare it to an autoscaling group for tasks/containers. It specifies where our tasks will run (instances that are part of the cluster) and also how they register themselves to the load balancer to receive traffic (ports, target groups).
ECS Task
This is the instantiation of the task definition where we specify how the service's containers should be built. The task definition contains information such as container image, environment variables (i.e. the different DynamoDB tables name), container port, and log configuration for each container. I decided to define both service containers in one task definition even though they are not linked and do not share information. This will ensure that we always have the same number of containers per service per task. In the Kubernetes world, that will mean having both containers running inside a single pod so both can scale at the same time. I would compare a Task to a Pod.
Depending on your application, you can choose to define one service container per task definition, where services will benefit from being independently scalable.
Application Load Balancer
With a task definition registered, we are ready to provide the infrastructure needed for our backend. Rather than directly exposing our services to the Internet, we will provide an Application Load Balancer (ALB) to sit in front of our services tiers. This would enable our frontend website code to communicate with a single DNS name while our backend service would be free to elastically scale in and out based on demand or if failures occur and new containers need to be provisioned.
For this application, we want to create one target group per service - so two target groups in total. By doing this, we make sure that the health of our services is evaluated individually and that some unhealthy containers for the main service do not affect the files service. Having two target groups will also help the load balancer identify what request goes to what containers (service) based on the path. The ALB Listener rules will help with that: main service requests go to main service containers, files service requests go to files service containers.
Authentication
Authentication is handled by AWS Cognito + API Gateway. We use a Cognito user pool to store users' data. When a user logs in and a session is established with the app, the session token and related data are stored at the Frontend and sent over to the API endpoints. API Gateway then validates the session token against Cognito and allows users to perform application operations. We use the API endpoints as HTTP proxies which forward traffic to the ALB. Requests are routed based on their path to the appropriate service containers.
Data Layer
DynamoDB and S3 are used to store all todos and related data. Our Flask app will be performing all Database and S3 operations connecting to the table and bucket, and getting requests from the frontend. DynamoDB and S3 are serverless services that provide auto-scaling along with high availability and durability.
Application Architecture
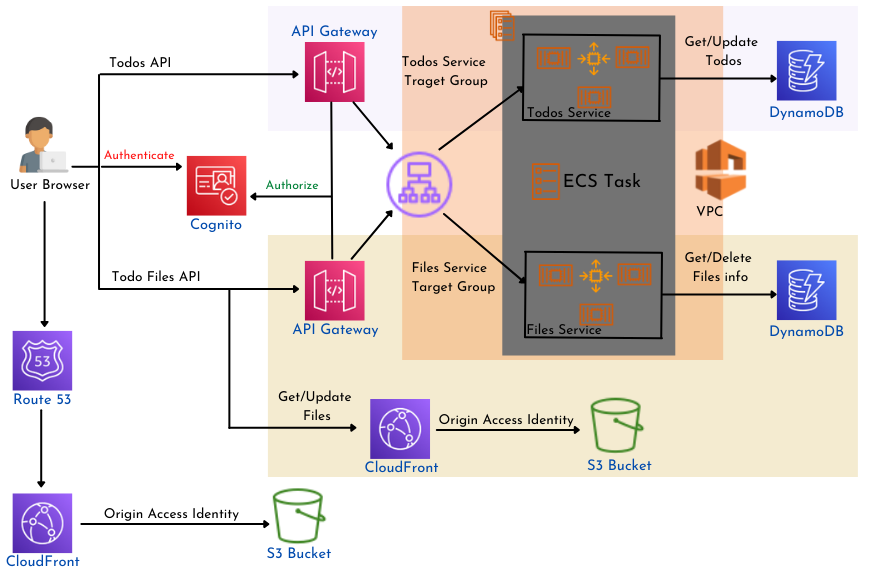
The main difference with the serverless version of this app is on the backend side. Instead of API + Lambda, we now have API + ALB + ECS + plus some magic to make them work together. We also have to manage how the ECS stack scales to accommodate traffic. Let's describe the backend.
VPC and components
Before we get to define your ECS service and task, we need to build a secure and highly available infrastructure to host our containers.
- For the sake of cost-saving, we went with the default VPC and preexisting subnets.
- A total of 6 subnets is required to achieve HA - 3 private and 3 public subnets. Make sure to set up your routing tables accordingly.
- We configured 2 security groups: one for the ALB allowing ingress traffic from the internet, and one for the containers instances (EC2s hosting the containers) allowing ingress only from the ALB security group. Here, make sure to allow traffic from port 31000 to 61000 (those ports are probably used by the Load balancer to map target groups).
IAM
We created 4 IAM roles as follows:
ECS Service Role: Amazon ECS uses the service-linked role named AWSServiceRoleForECS to enable Amazon ECS to call AWS APIs on your behalf. The AWSServiceRoleForECS service-linked role trusts the ecs.amazonaws.com service principal to assume the role. The role permissions policy allows Amazon ECS to complete actions on resources such as Rules which allow ECS to attach network interfaces to instances, Rules which allow ECS to update load balancers, Rules that let ECS interact with container images, Rules that let ECS create and push logs to CloudWatch.
ECS Task Role: With IAM roles for Amazon ECS tasks, you can specify an IAM role that can be used by the containers in a task. This is where we defined access permissions to the DynamoDb table and the S3 bucket. You also need to add rules to Allow the ECS Tasks to download images from ECR and
Allow the ECS tasks to upload logs to CloudWatch.EC2 Instance Role: This role is required for the container instance to be able to serve a cluster and also push logs to Cloudwatch.
The last role is for the application auto-scaling group for ECS which allows it to automatically scale resources (containers) based on a predefined scaling policy.
Application Load Balancer
The load balancer is deployed on the public subnets and will have the below components:
2 Target Groups
Since our application has 2 services, we need to create one target group for each, in other to forward requests to proper containers and also monitor the health of services independently.
ALB Listner and Listerner Rules
The listener rules will handle requests routing to the appropriate service based on a path pattern:
- requests with paths like ' **/todos** ' will be forwarded to the main service containers
- requests with paths like ' **/files** ' will be forwarded to the files service containers
Auto-scaling
We need to implement auto-scaling in two places:
Application auto-scaling
How do we scale our service containers when there is a traffic spike? Application auto-scaling. We created a CloudWatch Alarm to check for the HTTPCode_ELB_5XX_Count metric on the load balancer and trigger a scaling policy when the count is 10 for a period of 60 seconds. When triggered, the application scaling policy doubles the number of tasks, which in our case scales both services at the same time.
EC2 auto-scaling
So they have been a lot of HTTPCode_ELB_5XX errors and our containers have increased in number to accommodate the traffic. Containers run on EC2 and more containers mean fewer resources available for our container instances. We need to set up an auto-scaling group to spin up new instances when necessary. The container Instances will be deployed in the private subnets.
API Gateway
You may ask yourself why we need an API gateway while we already have the ALB which can be accessed on the frontend to serve requests. Well, the reason for having an API gateway here is to handle authentication with Cognito. It is also quite easier to set CORS in the API gateway. After authorizing the request against Cognito, the API will forward it to ALB which acts as an HTTP proxy.
Now that we have a description of how the components work together, we can discuss the deployment methods for the application.
Security
Security groups are defined so that only the load balancer can talk to the containers. No traffics coming from the internet is directly routed to the containers. The backend is isolated in private networks. Also, requests must be authorized by API Gateway before they get to the load balancer.
With the current configs, the backend sends data over the internet to retrieve/store data from DynamoDB and S3. You can do it in a more secure way by implementing VPC endpoints for the DynamoDB table and the S3 bucket. All backend traffic will then reside in the private networks.
IaC and Deployment Pipeline
The will be 4 different pipelines to deploy our application: one per backend service, one for core resources of the backend, and one for the frontend. We decided to use a Github repository and Github actions for workflows.
Frontend
The frontend pipeline is pretty straightforward. The code is pushed to the S3 website bucket whenever the frontend folder is updated in the repository.
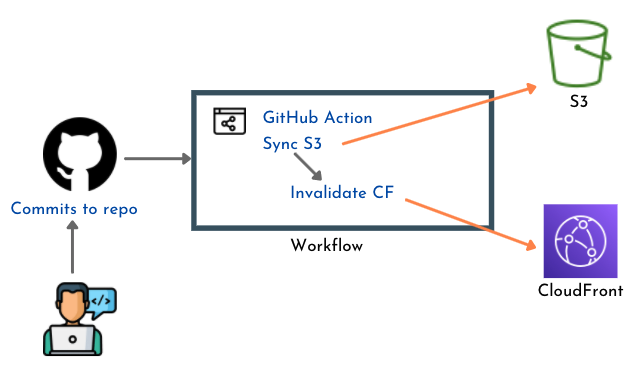
Backend core components
By core components, I mean VPC and related resources, ALB, ECS Cluster service and task, Launch configuration for EC2, API gateway, IAM roles... All resources are defined inside a SAM template. There is also a different template to spin up the website (CloudFront, S3, OAI). Every time the templates changed, a Cloudformation changeset is generated and the stack gets updated.
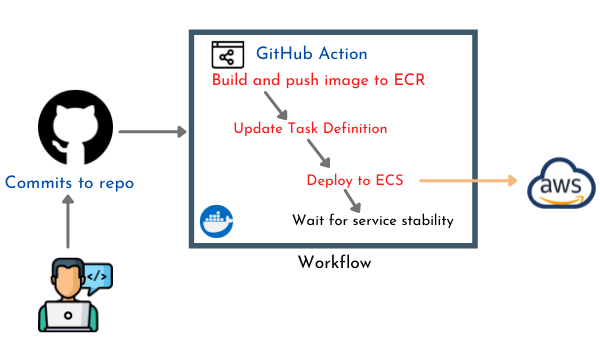
Backend services
The backend code is dockerized and images are pushed to our private ECR repository. The ECS task definition is then updated with the new image tag and redeployed to ECS. This happens every time the backend code is updated. Each service got a separate pipeline.
Takeaways
Go for Serverless!
While I had fun spinning up containers with ECS, I found the operations burden (setting up the VPC, ensuring HA with scaling group and policies...) a lot heavier than when deploying serverless resources. Not to talk about the cost of having EC2s running at all times - especially when you cannot predict traffic. It is true that some applications use cases require the exclusive use of containers. But now with more AWS services being serverless friendly, it is easier to redesign existing apps to take advantage of that. And if you absolutely need to run containers, maybe because the app requires a rich ecosystem, well AWS App Runner can do it for you while abstracting a lot of infrastructure provisioning. And if you need deeper control over your infrastructure, go for Kubernetes.
PS: I am preparing for the CKA exam at the time of publishing this blog post.